
")
Over-sampling the minority class in the feature space
María Pérez-Ortiz1, Pedro Antonio Gutiérrez1, Peter Tino2 and César Hervás-Martínez1
1Department of Computer Science and Numerical Analysis, University of Córdoba, Rabanales Campus, C2 building, 14004 - Córdoba, Spain.
2School of Computer Science, The University of Birmingham, Birmingham B15 2TT, United Kingdom.
e-mail: Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
This page provides supplementary material for the experimental results in the paper entitled Over-sampling the minority class in the feature space submitted to IEEE Transactions on Neural Networks and Learning Systems.
Abstract of the paper
The imbalanced nature of some real-world data is one of the current challenges for machine learning researchers, giving rise to several approaches to handle it; one of the most common one being convex combination of minority class patterns. This paper tries to explore in depth the notion of synthetic over-sampling in the feature space induced by a kernel function. The main motivation is that the feature space would provide a better class spatial distribution for over-sampling than the input space given that, ideally, if the kernel function matches the underlying problem, the separation function will be linear and therefore, synthetically generated patterns will lie on the minority class region. Since the feature space is not accessible, because the only information available is the dot product between points, the notion of empirical feature space is used for over-sampling purposes (which is a Euclidean space isomorphic to the original feature space). The proposed method is tested in the context of Support Vector Machines (SVM) where imbalanced datasets pose a serious hindrance for learning, although by definition, the methodology could be applied to any classifier. A flexible kernel learning technique, that maximises the data class separation, is also used to validate the initial hypothesis and to study the influence of the kernel function in the method. Finally, we derive an unified framework for preferential over-sampling (i.e., that analyse the more suitable patterns to be over-sampled) using the optimal SVM hyperplane solution and kernel learning techniques. A thorough set of experiments over 50 binary imbalanced datasets is conducted to validate the main hypotheses of this work.
The additional information provided for the experimental section is the following:
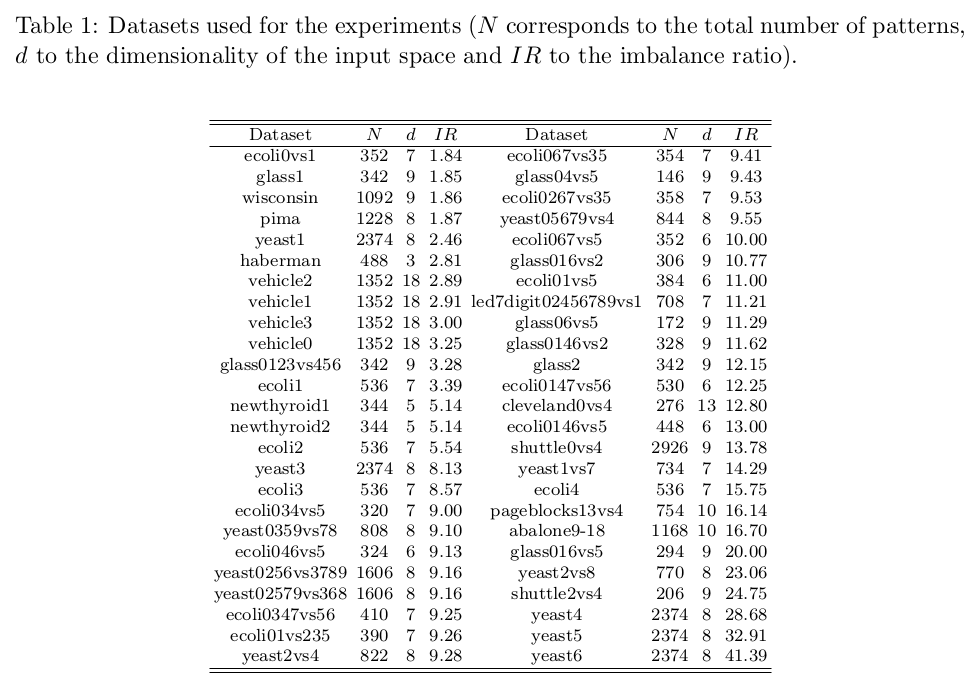
- Datasets: The performance of the methods is analysed by using a set of 50 publicly available datasets. The main characteristics of these datasets can be seen in Table 1, where the name, number of patterns, attributes and imbalanced ratio were reported. Regarding the experimental setup, the datasets have been partitioned by a stratified 5x2 Dietterich procedure. The following link contains the whole set of data partitions in Weka, LibSVM and matlab formats.
 5x2Dietterich-binary-imbalanced-datasets.tar.gz
5x2Dietterich-binary-imbalanced-datasets.tar.gz
- Code for the algorithms: The code in Matlab for all the algorithms can be accessed in the following link: algorithmsCode.tar.gz
- Detailed results for the experiments: The complete set of results in terms of the two evaluation metrics for the 8 considered methods and 50 datasets can be found in the following link: DetailedResults.pdf