
")
Ordinal regression methods: survey and experimental study
Pedro Antonio Gutiérrez, María Pérez-Ortiz, Javier Sánchez-Monedero, Francisco Fernández-Navarro, and César Hervás-Martínez
Department of Computer Science and Numerical Analysis, University of Córdoba, Rabanales Campus, C2 building, 14004 - Córdoba, Spain.
e-mail: Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. ,Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. ,Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. ,Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo. ,Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
This page provides supplementary material for the paper entitled Ordinal regression methods: survey and experimental study, IEEE Transactions on Knowledge and Data Engineering, vol 28 (1), pp. 127-146.
GitHub repository: https://github.com/ayrna/orca
Link to the paper: http://dx.doi.org/10.1109/TKDE.2015.2457911
Abstract of the paper
Ordinal regression problems are those machine learning problems where the objective is to classify patterns using a categorical scale which shows a natural order between the labels. Many real-world applications present this labelling structure and that has increased the number of methods and algorithms developed over the last years in this field. Although ordinal regression can be faced using standard nominal classification techniques, there are several algorithms which can specifically benefit from the ordering information. Therefore, this paper is aimed at reviewing the state of the art on these techniques and proposing a taxonomy based on how the models are constructed to take the order into account. Furthermore, a thorough experimental study is proposed to check if the use of the order information improves the performance of the models obtained, considering some of the approaches within the taxonomy. The results confirm that ordering information benefits ordinal models improving their accuracy and the closeness of the predictions to actual targets in the ordinal scale.
The algorithms selected for comparison in the study are the following ones:
- Support Vector Classifier with OneVsOne (SVC1V1) [1]: Nominal Support Vector Machine performing the OneVsOne formulation (considered as a naïve approach for ordinal regression since it ignores the order information).
- Support Vector Classifier with OneVsAll (SVC1VA) [1]: Nominal Support Vector Machine with the OneVsAll paradigm (considered as a naïve approach for ordinal regression since it ignores the order information).
- Support Vector Machines for regression (SVR) [2]: Standard Support Vector Regression with normalised targets (considered as a naïve approach for ordinal regression since the assumption of equal distances between targets is done).
- Cost-Sensitive Support Vector Classifier (CSSVC) [1]: This is a nominal SVM with the OneVsAll decomposition, where absolute costs are included as different weights for the negative class of each decomposition (it is considered as a naïve approach for ordinal regression since the assumption of equal distances between classes is done).
- Support Vector Machines with OrderedPartitions (SVMOP) [3], [4]: Binary ordinal decomposition methodology with SVM as base method, it imposes explicit weights over the patterns and performs a probabilistic framework for the prediction.
- Neural Network with OrderedPartitions (NNOP) [5]: Generalization of the perceptron learning for Ordinal Regression by using the ordered partitions framework and a methodology for ignoring prediction inconsistencies.
- Extreme Learning Machine with OrderedPartitions (ELMOP) [6]: Standard Extreme Learning Machine imposing an ordinal structure in the coding scheme representing the target variable.
- Proportional Odd Model (POM) [7]: Extension of the linear binary Logistic Regression methodology to Ordinal Classification by means of Cumulative Link Functions.
- Neural Network based on Proportional Odd Model (NNPOM) [8]: Non-linear version of the POM model by using Neural Networks and a maximum likelihood maximization methodology for setting the network parameters.
- Support Vector Ordinal Regression with Explicit Constraints (SVOREX) [9]: Ordinal formulation of the SVM paradigm, which computes discriminant parallel hyperplanes for the data and a set of thresholds by imposing explicit constraints in the optimization problem.
- Support Vector Ordinal Regression with Implicit Constraints (SVORIM) [9]: Ordinal formulation of the SVM paradigm, which computes discriminant parallel hyperplanes for the data and a set of thresholds by imposing implicit constraints in the optimization problem.
- SVORIM using a linear kernel (SVORLin) [9]: We have also included a linear version of the SVORIM method (considering the linear kernel instead of the Gaussian one) to check how the kernel trick affects the final performance (SVORLin).
- Kernel Discriminant Learning for Ordinal Regression (KDLOR) [10]: Reformulation of the well-known Kernel Discriminant Analysis for Ordinal Regression by imposing an order constraint in the projection to compute.
- Gaussian Processes for Ordinal Regression (GPOR) [11]: Bayesian framework for modelling the latent variable inherent to an ordinal structure.
- Reduction applied to Support Vector Machines (REDSVM) [12]: Augmented Binary Classification framework that solves the Ordinal Regression problem by a single binary model (SVM is applied in this case).
- Ordinal Regression Boosting with All margins (ORBAll) [13]: This is an ensemble model based on the threshold model structure, where normalised sigmoid functions are used as the base classifier.
The taxonomy for ordinal regression methods proposed by the authors can be seen in Fig. 1, where the methodologies have been categorised in the following families:
- Naïve approaches: Ordinal regression problems are usually simplified to other standard machine learning problems, such as multinomial and cost-sensitive classification or regression. The multiclass formulations of SVM (SVC1V1 and SVC1VA) and a cost-sensitive version of SVC1VA (CSSVC) are considered in this group, together with the SVR method.
- Binary decompositions: This group includes all those methods which are based on decomposing the ordinal target variable into several binary ones, which are then estimated by a single or multiple models. SVMOP, NNOP and ELMOP are the ones considered of this section for the experiments.
- Threshold models: This methodology is one of the most popular approach for modelling ordinal problems and they are based on the assumption that an unobserved continuous variable underlies the ordinal response. The algorithms POM, NNPOM, SVOREX, SVORIM, SVORLin, KDLOR, GPOR and ORBAll are the threshold models tested in this work. Reduction framework (REDSVM) is also included in this group, because the final model obtained is basically a threshold model.
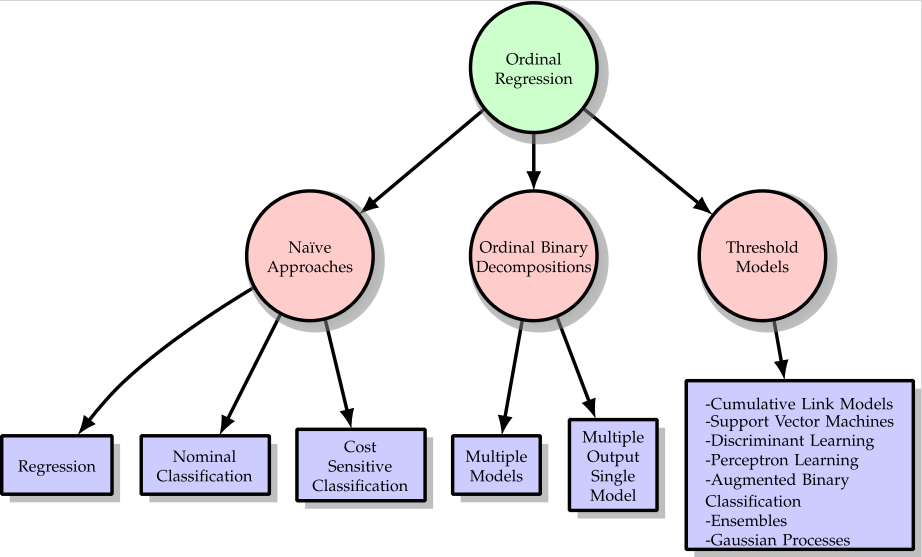
Fig. 1.: Proposed taxonomy of ordinal regression methods.
The additional information provided for the experimental section is the following:
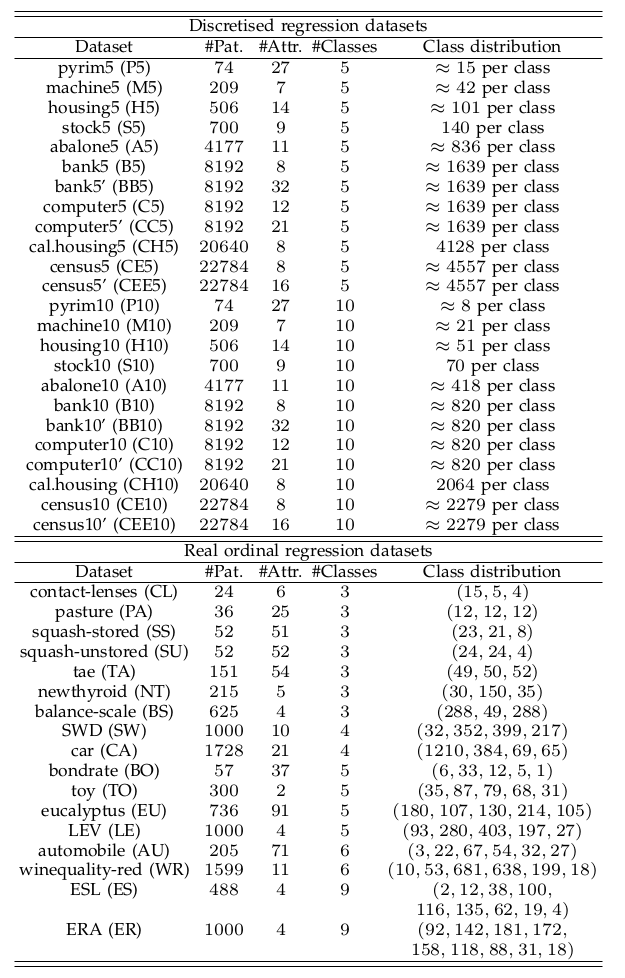
- Datasets: The performance of ordinal regression methods is analysed by using a set of 41 publicly available datasets (17 concerning real ordinal classification and 24 discretised regression). The main characteristics of these datasets can be seen in Table 1, where the name, number of patterns, attributes, classes and distribution are reported. Regarding the experimental setup, the datasets have been partitioned by a 30-holdout procedure (for the real ones) and a 20-holdout (for the discretised ones). The following link contains the whole set of data partitions in Weka, LibSVM and Matlab formats.
 datasets-orreview.zip
datasets-orreview.zip
Table 1: Characteristics of the benchmark datasets.
- Detailed results: The full results obtained for each data partition in the experimental study can be seen in the following link, where the experimental section has been divided in two parts: Real datasets and discretized regression ones. The performance of each one of the methodologies tested can be seen in a different file (.csv) reporting MZE, MAE and Time measures. detailed-results.zip
- Statistical tests: Statistical analysis are carried out by means of nonparametric statistical tests. The Wilcoxon test is used in order to conduct pairwise comparisons among all classifiers considered in the study. Specifically, the Wilcoxon test is adopted in this study considering a level of significance equal to α = 0.10. In this case, the results of the Wilcoxon test are provided for every performance measure and dataset used in this study in .csv format. statistical-tests.zip
- Ordinal Algorithms Matlab Framework and other software: The code of all the algorithms is available within the following GitHub repository.
Bibliography
[1] C.-W. Hsu and C.-J. Lin, “A comparison of methods for multi-class support vector machines,” IEEE Transaction on Neural Networks, vol. 13, no. 2, pp. 415–425, 2002.
[2] A. Smola and B. Schölkopf, “A tutorial on support vector regression,” Statistics and Computing, vol. 14, no. 3, pp. 199–222, 2004.
[3] E. Frank and M. Hall, “A simple approach to ordinal classification,” in Proceedings of the 12th European Conference on Machine Learning, ser. EMCL ’01. London, UK: Springer-Verlag, 2001, pp. 145–156.
[4] W. Waegeman and L. Boullart, “An ensemble of weighted support vector machines for ordinal regression,” International Journal of Computer Systems Science and Engineering, vol. 3, no. 1, pp. 47–51, 2009.
[5] J. Cheng, Z. Wang, and G. Pollastri, “A neural network approach to ordinal regression,” in Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN2008, IEEE World Congress on Computational Intelligence). IEEE Press, 2008, pp. 1279–1284.
[6] W.-Y. Deng, Q.-H. Zheng, S. Lian, L. Chen, and X. Wang, “Ordinal extreme learning machine,” Neurocomputing, vol. 74, no. 1–3, pp. 447– 456, 2010.
[7] P. McCullagh, “Regression models for ordinal data,” Journal of the Royal Statistical Society. Series B (Methodological), vol. 42, no. 2, pp. 109–142, 1980.
[8] M. J. Mathieson, “Ordinal models for neural networks,” in Proceedings of the Third International Conference on Neural Networks in the Capital Markets, ser. Neural Networks in Financial Engineering, J. M. A.-P. N. Refenes, Y. Abu-Mostafa and A. Weigend, Eds. World Scientific, 1996, pp. 523–536.
[9] W. Chu and S. S. Keerthi, “Support Vector Ordinal Regression,” Neural Computation, vol. 19, no. 3, pp. 792–815, 2007.
[10] B.-Y. Sun, J. Li, D. D. Wu, X.-M. Zhang, and W.-B. Li, “Kernel discriminant learning for ordinal regression,” IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 6, pp. 906–910, 2010.
[11] W. Chu and Z. Ghahramani, “Gaussian processes for ordinal regression,” Journal of Machine Learning Research, vol. 6, pp. 1019–1041, 2005.
[12] H.-T. Lin and L. Li, “Reduction from cost-sensitive ordinal ranking to weighted binary classification,” Neural Computation, vol. 24, no. 5, pp. 1329–1367, 2012.
[13] H.-T. Lin and L. Li, “Large-margin thresholded ensembles for ordinal regression: Theory and practice,” in Proc. of the 17th Algorithmic Learning Theory International Conference, ser. Lecture Notes in Artificial Intelligence (LNAI), J. L. Balcazar, P. M. Long, and F. Stephan, Eds., vol. 4264. Springer-Verlag, October 2006, pp. 319–333.