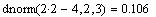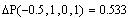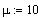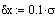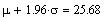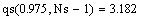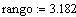Funciones de distribución de datos
Distribución Gaussiana:
La función Gaussiana o función de distribución normal viene dada por:
Donde m es el valor medio y s la desviación standard. El caso especial en el que m=0 and s=1 (dnorm(x,0,1)) se conoce como Gaussiana standard. Cualquier distribución Gaussiana puede expresarse de acuerdo a una Gaussiana standard mediante el cambio de variable z = (x-m)/s.
La probabilidad de encontrar un valor x, comprendido en el intervalo [x, x+dx], viene dada por:
dnorm(x,m,s)dx.
Lo anterior es rigurosamente cierto solo en el límite dx ---> 0, aunque es también una buena aproximación para dx finito, siempre que dx << s.
Una propiedad de esta función es su caracter simétrico, es decir dnorm(x,m,s) = dnorm(2m-x,m,s)
La probabilidad de que x sea menor que a, segun una distribución Gaussiana viene dada por:
A esta función se le conoce como función Gaussiana acumulada. La probabilidad total será:
Podemos expresar la probabilidad de encontrar el valor de x comprendido en el intervalo [a,b] (a<b) como:
A menudo, es necesario determinar la inversa de la función pnorm, es decir, el valor de a, tal que la probabilidad de que x<a, tenga un valor concreto p.
La función
root
necesita de un valor de prueba, que llamamos apro (valor aproximado de a), la función qnorm, retorna el valor correcto de a aunque esta es una función numérica que en ocasiones necesita de un cálculo refinado. La función TOL:= 10-11, controla la precición del cálculo.
Veamos como funciona. Imaginemos una distribución standar, para la que queremos calcular el valor de a, tal que la probabilidad acumulada sea del 95% (p=0.95). Vamos a empezar con ap = 0.5
Podemos ahora calcular que efectivamente, para esta distribución, la probabilidad de que x<a es del 95%
Las funciones pnorm(x,m,s):=a y qnorm(a,m,s):=x, son por lo tanto funciones inversas.
Generación de un conjunto de datos de acuerdo a una distribución Gausssiana.
Existen muchas situaciones en la que se necesita generar puntos distribuidos de acuerdo a una Gaussiana.
El método de Box-Muller permite generar desviaciones normales con media y desviación estándar aplicando la fórmula siguiente
La función rnd(x) genera un número
aleatorio comprendido entre 0 y 1
Veamos un ejemplo:
Número de datos
Si chequeamos nuetros datos
Estos valores no son los exactos debido a fluctuaciones, lo que se debe a que el número de datos de que se dispone es finito.Vamos a representar una fracción de nuestros datos:
Esta representación se parece mucho a lo que se ve en un osciloscopio cuando se dispone de un buen amplificador. Este tipo de curva esta afectada por lo que se denomina ruido, y consta de una banda centrada en m, con anchurade ~5s. Vamos a comparar estos datos con una distribución Guassiana
x representa una cierta anchura de banda. Nuestros datos los vamos a dividir en 100 grupos o intervalos (i :=0..99) distribuidos desde m+5s hasta m-5s. Dicho agrupamiento se hace con la función hist(x,z) (histrograma de x,z). Esta función crea un vector de 100 puntos, en el que en cada elemento representa la frecuencia con la que aparece cada valor de z.
La distribución Gaussiana teórica será
Si representamos f y f2
Intervalo de Confianza
Una medida científica no esta completa si no se estima el error que conlleva. Si se conoce la desviación standar, la función qnorm nos permite realizar una estimación de esta cantidad. Vamos a definir la función:
Esta función nos da el Intervalo de confianza para una distribución normal, donde p es el nivel de probabilidad.
Notese que:
Luego esta función nos da los valores de x (superior e inferior) que encierran una cierta probabilidad de
encontrar un resultado.
Calculemos el intervalo de probabilidad para un límite de confianza del 95%
Recuerdese que apro y bpro son valores de prueba, y necesitamos modificarlos hasta que se obtiene una solución convergente
Es decir, el 95% de los datos estan situados en el intervalo de x que va de m-1.96s a m+1.96s. Para nuestros datos
La región sombreada es la correspondiente a un intervalo de confianza del 95%
Con esta expresión calculamos la fracción de puntos experimentales que estan situados fuera del intervalo de confianza. El resultado debe ser próximo al 5% (0.05). zi<bajo da 1 si es verdad y cero si es falso.
De esta forma se puede estimar el error (Confianza) si s es conocida. żPero como se determina esta magnitud?
En muchas aplicaciones estadísticas se necesita conocer el valor de s. Este valor no se puede medir experimentalemente, pero es posible estimarlo mediante un número finito de medidas. Vamos a repartir nuestros datos en conjuntos de Ns datos.
Numero de puntos por conjunto de datos
Numero de conjunto de datos. Es decir, nuestros 10000 datos lo vamos a transformar en 2500, de forma que cada punto es en realidad la media de 4 datos.
Creamos un vector, promedio, en el que cada dato es en realidad la media de 4 datos.
Para este vector:
Estimación de la desviación standard de una distribución a partir de un conjunto de datos
Primero estimaremos la varianza mediante la siguiente expresión:
Esta función determina la varianza de cada uno de los Nt conjuntos de datos
El valor medio de la varianza es una buena estimación de s2
La función de distribución Chi al cuadrado, c2:
Esta forma de calcular la desviación standard, s, es correcta para otras funciones de distribución. Sin embargo, para saber lo buena que es la estimación de s, necesitamos conocer cual es la distribución de las varianzas de la muestra. En teoría estadística se comprueba que la función de distribución para la varianza de las muestras, puede ser expresada en términos de la función de distribución c2 ( función chi al cuadrado) definida como:
En esta función x> = 0 y d es un entero >0, llamado grados de libertadd.
El símbolo G(d/2) representa la
función gamma de Euler
de argumenro d/2.
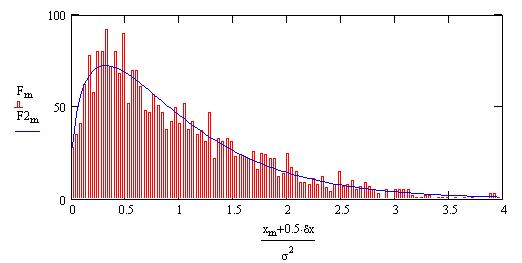
Vamos a comparar la distribución observada de los valores de las varianzas de las muestras vark, con las predicciones de la distribución c2:
Esto nos permite crear segmentos espaciados 0.04s2
Introducimos las varianzas en dichos segmentos
Creamos una variable de intervalo m, cuyo tamańo es uno menos que el número de segmentos.
Grados de libertad
Esta expresión nos permite predecir, de acuerdo a la distribución c2, el número de puntos en cada segmento centrado en el valor (xm + xm+1)/2
Esta gráfica nos enseńa que si el tamańo de la muestra de datos es pequeńo, el valor de la desviación standard calculado puede ser muy diferente del real. Lo normal es que el valor s calculado sea inferior al real. Este error es bastante frecuente.
Para comprobar este efecto, vamos a calcular con que frecuencia nuestros valores medios (avg) difieren una cantidad superior a 2s del valor s.
Cantidad superior al 5% (13.8%) que es lo que cabe esperar para una distribución normal.
Si usamos el valor verdadero de s
Lo que es proximo al 5%, como cabe esperar para una distribución Gaussiana.
Por lo tanto el problema sigue existiendo, ya que no es posible estimar el error, si además tenemos que calcular también s a partir de los datos experimentales. Para resolver este problema suele utilizarse la distribución t de student.
Distribución de Student:
La distribución de Student se define como la relación:
La distribución de student tiende a la distribución Gaussiana normal cuando d tiende a infinito
Podemos definir las funciones acumulada y acumulada inversa de Student, de forma simular a como se hizo con la Gaussiana
Podemos también definir el intervalo de confianza como
Por ejemplo, los valores de x para un intervalo de confianza del 95% son, como el de nuestro ejemplo son:
Llamaremos
Vamos a chequear la fracción de medias de muestras que difieren de m más que el rango predicho por la distribución de student.
Muy proximo al 5% que cabe esperar